The Core Problem¶
Scientific and engineering organizations face a fundamental challenge: as data volumes grow and analyses become more complex, traditional approaches break down. File-based workflows become unmaintainable. Metadata gets separated from the data it describes. Computational provenance is lost. Teams duplicate effort because they cannot discover or trust each other’s work. Reproducing results requires archaeological expeditions through old scripts and folder structures.
Standard database solutions address storage and querying but not computation. Data warehouses and lakes handle scale but not scientific workflows. Workflow engines (Airflow, Luigi, Snakemake) manage task orchestration but lack the data model rigor needed for complex analytical dependencies. The result is a patchwork of tools that don’t integrate cleanly, requiring custom glue code that itself becomes a maintenance burden.
The DataJoint Solution¶
DataJoint introduces the Relational Workflow Model—an extension of classical relational theory that treats computational transformations as first-class citizens of the data model. The database schema becomes an executable specification: it defines not just what data exists, but how data flows through the pipeline and when computations should run.
This creates what we call a Computational Database: a system where inserting new raw data automatically triggers all downstream analyses in dependency order, maintaining computational validity throughout. Think of it as a spreadsheet that auto-recalculates, but with the rigor of a relational database and the scale of distributed computing.
Key Differentiators¶
Unified Design and Implementation Unlike Entity-Relationship modeling that requires translation to SQL, DataJoint schemas are directly executable. The diagram is the implementation. Schema changes propagate immediately. Documentation cannot drift from reality because the schema is the documentation.
Workflow-Aware Foreign Keys Foreign keys in DataJoint do more than enforce referential integrity—they encode computational dependencies. A computed result that references raw data will be automatically deleted if that raw data is removed, preventing stale or orphaned results. This maintains computational validity, not just referential integrity.
Declarative Computation Computations are defined declaratively through make() methods attached to table definitions. The populate() operation identifies all missing results and executes computations in dependency order. Parallelization, error handling, and job distribution are handled automatically.
Immutability by Design Computed results are immutable. Correcting upstream data requires deleting dependent results and recomputing—ensuring the database always represents a consistent computational state. This naturally provides complete provenance: every result can be traced to its source data and the exact code that produced it.
Hybrid Storage Model Structured metadata lives in the relational database (MySQL/PostgreSQL). Large binary objects (images, recordings, arrays) live in scalable object storage (S3, GCS, filesystem) with the database maintaining the mapping. Queries operate on metadata; computation accesses objects transparently.
Architecture Overview¶
The DataJoint Platform implements this model through a layered architecture:
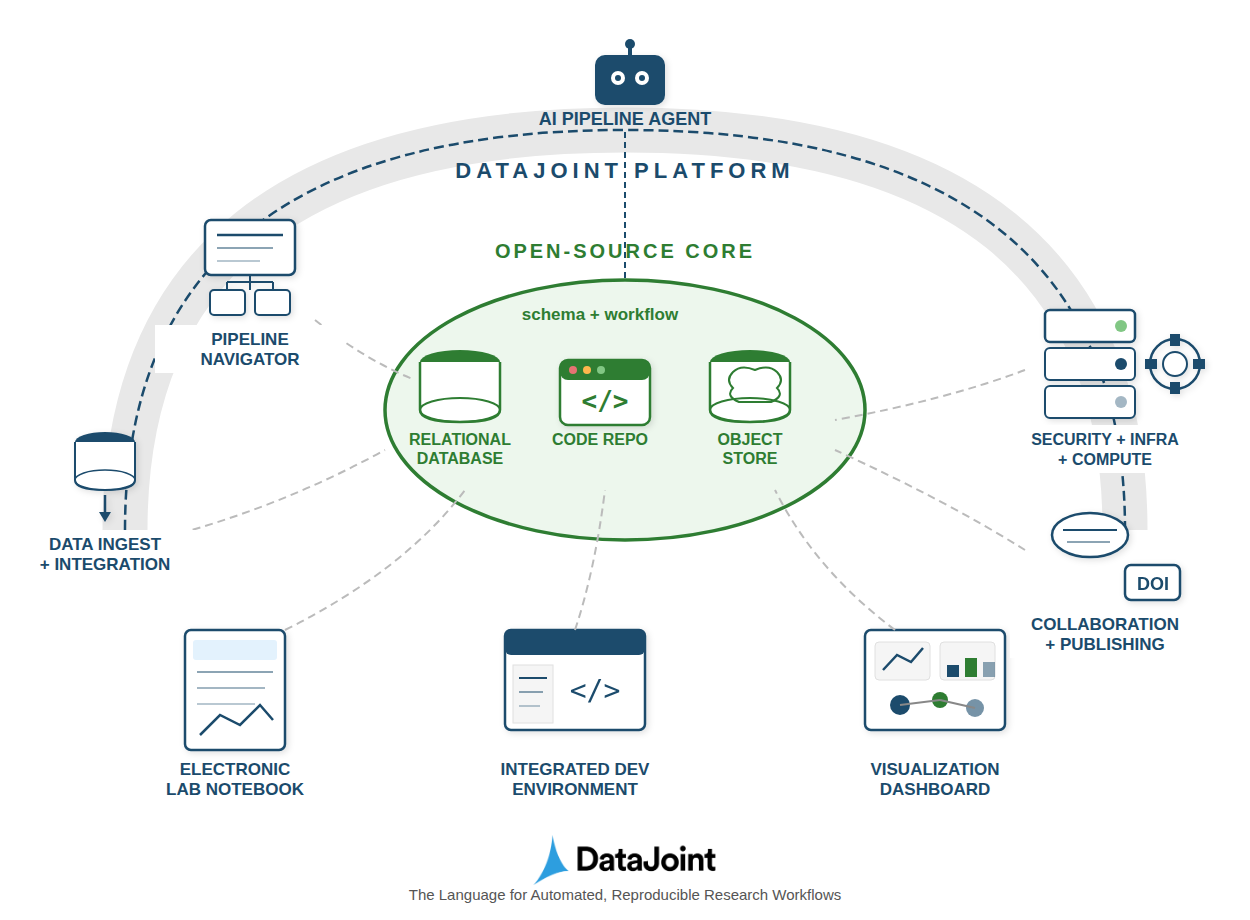
Figure 1:The DataJoint Platform architecture: an open-source core (relational database, code repository, object store) surrounded by functional extensions for interactions, infrastructure, automation, and orchestration.
Open-Source Core
Relational database (MySQL/PostgreSQL) as system of record
Code repository (Git) containing schema definitions and compute methods
Object store for large data with structured key naming
Functional Extensions
Interactions: Pipeline navigator, electronic lab notebook integration, visualization dashboards
Infrastructure: Security, deployment automation, compute resource management
Automation: Automated population, job orchestration, AI-assisted development
Orchestration: Data ingest, cross-team collaboration, DOI-based publishing
The core is fully open source. Organizations can build DIY solutions or use managed platform services depending on their needs.
What This Book Covers¶
This book provides comprehensive coverage of DataJoint from foundations through advanced applications:
Part I: Concepts
Database fundamentals and why they matter for scientific work
Data models: schema-on-write vs. schema-on-read, and why schemas enable mathematical guarantees
Relational theory: the 150-year mathematical foundation from De Morgan through Codd
The Relational Workflow Model: DataJoint’s extension treating computation as first-class
Scientific data pipelines: complete systems integrating database, compute, and collaboration
Part II: Design
Schema design principles and table definitions
Primary keys, foreign keys, and dependency structures
Master-part relationships for hierarchical data
Normalization through the lens of workflow entities
Schema evolution and migration strategies
Part III: Operations
Data insertion, deletion, and transaction handling
Caching strategies for performance optimization
Part IV: Queries
DataJoint’s five-operator query algebra: restriction, projection, join, aggregation, union
Comparison with SQL and when to use each
Complex query patterns and optimization
Part V: Computation
The
make()method pattern for automated computationParallel execution and distributed computing
Error handling and resumable computation
Part VI: Interfaces and Integration
Python and MATLAB APIs
Web interfaces and visualization tools
Integration with existing data systems
Part VII: Examples and Exercises
Complete worked examples from neuroscience, imaging, and other domains
Hands-on exercises for each major concept
Who Should Use DataJoint¶
DataJoint is designed for organizations where:
Data has structure: Experiments, subjects, sessions, trials, measurements—your domain has natural entities and relationships
Analysis has dependencies: Results depend on intermediate computations that depend on raw data
Reproducibility matters: You need to trace any result back to its source data and methodology
Teams collaborate: Multiple people work with shared data and build on each other’s analyses
Scale is growing: What worked for one researcher doesn’t work for a team; what worked for one project doesn’t work for ten
DataJoint is used in over a hundred neuroscience labs worldwide, supporting projects of varying sizes and complexity—from single-investigator studies to large multi-site collaborations. It handles multimodal data spanning neurophysiology, imaging, behavior, sequencing, and machine learning, scaling from gigabytes to petabytes while maintaining the same rigor.
Getting Started¶
The Concepts section builds the theoretical foundation. If you prefer to learn by doing, the hands-on tutorial in Relational Practice provides immediate experience with a working database. The Design section then covers practical schema construction.
The Blob Detection example demonstrates a complete image processing pipeline with all table tiers (Manual, Lookup, Imported, Computed) working together, providing a concrete reference implementation.
The DataJoint Specs 2.0 provides the formal specification for those requiring precise technical definitions.
To evaluate DataJoint for your organization, visit datajoint.com to subscribe to a pilot project and experience the platform firsthand with guided support.